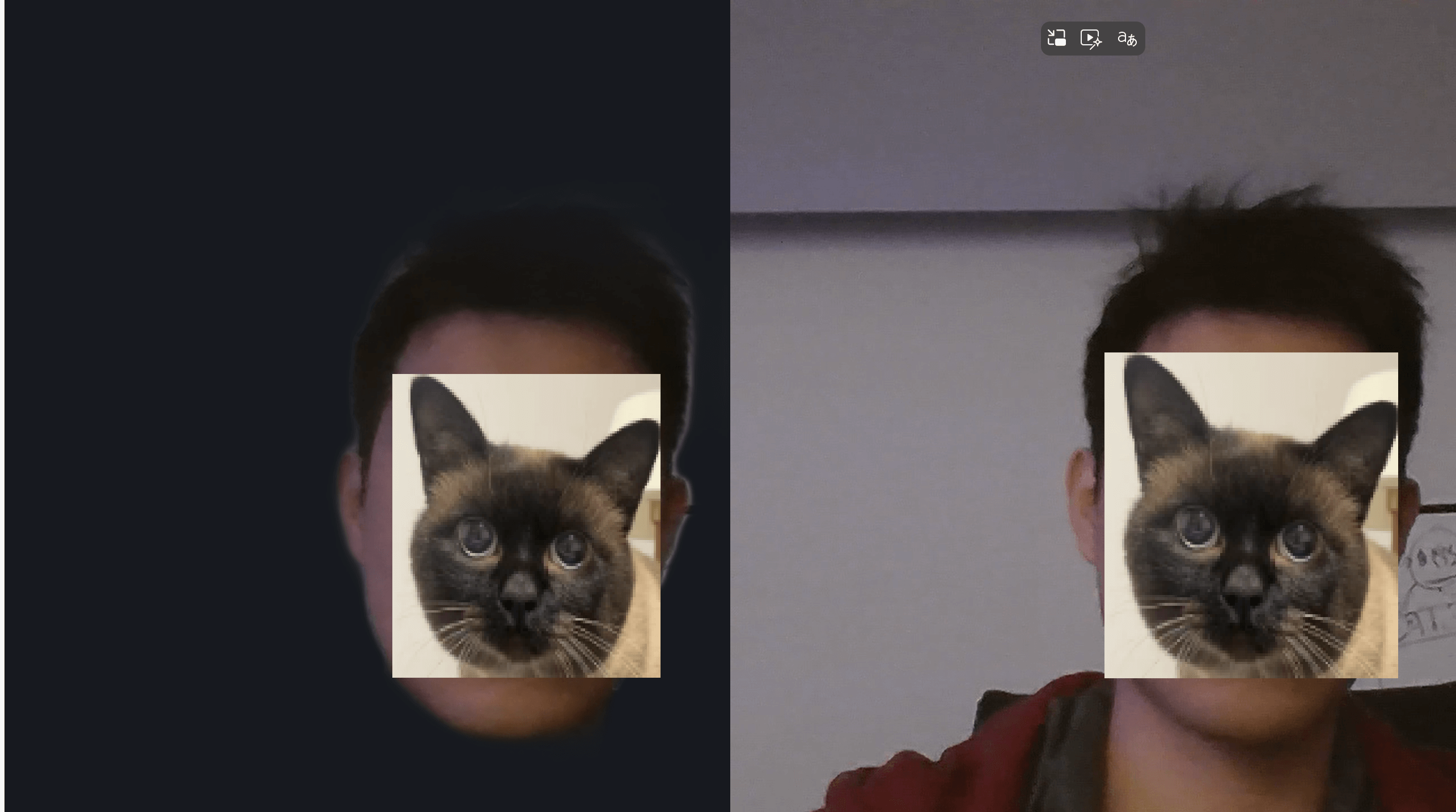
原理
U²-Net / U2Netpd
U²-Net 是一种用于前景分割/显著性检测的网络。它用带 U 形结构的残差块(RSU) 堆叠出多尺度特征,在较小模型体量下也能得到较好的前景/背景分离效果。U2Netp 是其轻量版(参数更少),适合浏览器端 320×320 输入下的实时应用。
- 输入:RGB 图像(将摄像头帧 letterbox 到 320×320)
- 输出:与输入等尺寸的单通道
alpha蒙版(值域 0~1),表示前景概率/不透明度。
ONNX推理负责 算出蒙版,而WebGL 负责 把蒙版与原视频合成成最终画面
- 直接在片段着色器中,根据 a = mask(u,v) 做 mix(bg, src, a);
- 这样能把放大采样、配准、合成一次完成,且在 GPU 上运行,减少 CPU 拷贝与 Canvas 像素级操作的开销。
数据流与坐标系
浏览器视频帧是任意分辨率(例如 1280×720),模型输入固定 320×320。为了不拉伸人像,用 letterbox 做前处理:
- 计算缩放
s = min(320/W, 320/H); - 缩放后尺寸
W' = W*s,H' = H*s; - 居中偏移
ox = (320-W')/2, oy = (320-H')/2; - 在 320×320 的离屏 Canvas 中
drawImage(video, 0,0,W,H, ox,oy, W',H'); - 读取
ImageData(320,320),拼出 CHW 的 Float32,[0,1] 归一化送入模型; - 获得 320×320 的蒙版后,在 WebGL 片段着色器里把屏幕坐标(同时也是视频 UV)映射回模型坐标:
vec2 px = uv * uVideoSize; // 屏幕 -> 视频像素
vec2 modelPx = px * uScale + uOffset; // 视频像素 -> 模型输入像素
vec2 muv = modelPx / 320.0; // 模型像素 -> [0,1]
float a = texture2D(uMask, muv).r; // 采样蒙版
Letterbox是一种图像调整技术,通过在图像的边缘填充一定数量的像素,使图像的尺寸满足特定的要求。这种技术主要用来调整图像的纵横比,以适应不同的模型输入尺寸。在深度学习中,Letterbox技术被广泛应用于计算机视觉任务,如目标检测、图像分类等。
获取摄像头与首帧
getUserMedia获取视频流并赋给<video>;- 必须等待
onloadedmetadata,再video.play(),此时videoWidth/Height才可靠; - 只有当
readyState >= HAVE_CURRENT_DATA时才开始渲染/推理。
const stream = await navigator.mediaDevices.getUserMedia({
video: { width: { ideal: 1280 }, height: { ideal: 720 } },
audio: false,
})
video.srcObject = stream
await new Promise<void>(res => {
if (video.readyState >= video.HAVE_METADATA) return res()
video.onloadedmetadata = () => res()
})
await video.play()
ONNX Runtime Web 与推理
直接上注释代码:
import * as ort from 'onnxruntime-web'
// 获取当前页面的基础 URL,用于拼接资源路径
const baseAbs = new URL(import.meta.env.BASE_URL, window.location.href)
// 设置 ORT 的 wasm 路径,确保模型推理时能正确加载 wasm 文件
ort.env.wasm.wasmPaths = '/ort/';
// 构造 JSEP 相关 wasm 和 mjs 文件的绝对路径
const mjsUrl = new URL('ort/ort-wasm-simd-threaded.jsep.mjs', baseAbs).toString()
const wasmUrl = new URL('ort/ort-wasm-simd-threaded.jsep.wasm', baseAbs).toString()
// 定义模型输出类型,mask 是 320x320 的 float32 数组,值域为 [0,1]
export type U2NOutput = {
mask: Float32Array // 320*320 floats, range [0,1]
}
// 初始化 ONNX Runtime Web 环境
export async function initOrt(): Promise<void> {
// 指定 ORT 查找 wasm 资源的路径,避免 public/ort 路径报错
ort.env.wasm.wasmPaths = {
mjs: mjsUrl,
wasm: wasmUrl,
}
// 设置为单线程,开发时避免跨域隔离带来的复杂性
ort.env.wasm.numThreads = 1
// 可选:开启调试日志
// ort.env.logLevel = 'info'
}
// 加载 U2Netp 模型,并返回推理相关方法
export async function loadU2Netp(modelUrl: string) {
// 只使用 WASM 推理后端
const session = await ort.InferenceSession.create(modelUrl, {
executionProviders: ['wasm'],
graphOptimizationLevel: 'all'
})
// 获取模型输出名称
const outputName = session.outputNames[0]
// 预分配输入张量缓冲区,避免频繁 GC
const INPUT_SIZE = 320
const CH = 3
const inputBuffer = new Float32Array(1 * CH * INPUT_SIZE * INPUT_SIZE)
// 创建可复用的输入张量对象
const inputTensor = new ort.Tensor('float32', inputBuffer, [1, CH, INPUT_SIZE, INPUT_SIZE])
// 从 ImageData 推理,返回 mask
async function inferFromImageData(imgData: ImageData): Promise<U2NOutput> {
// imgData 是 320x320 的 RGBA 图像
const { data, width, height } = imgData
const W = width, H = height
// 填充输入张量,格式为 CHW,归一化到 [0,1]
let p = 0
// R 通道
for (let i = 0; i < W * H; i++) inputBuffer[p++] = data[i * 4 + 0] / 255
// G 通道
for (let i = 0; i < W * H; i++) inputBuffer[p++] = data[i * 4 + 1] / 255
// B 通道
for (let i = 0; i < W * H; i++) inputBuffer[p++] = data[i * 4 + 2] / 255
// 构造输入字典
const feeds: Record<string, ort.Tensor> = {}
feeds[session.inputNames[0]] = inputTensor
// 执行推理
const results = await session.run(feeds)
// 获取输出张量
const out = results[outputName] as ort.Tensor
// 输出 shape 可能为 [1,1,320,320] 或 [1,320,320]
const dataOut = out.data as Float32Array
const mask = new Float32Array(320 * 320)
// 兼容不同输出 shape,提取前 320*320 个值
if (out.dims.length === 4) {
// [1,1,H,W]
for (let i = 0; i < 320 * 320; i++) mask[i] = dataOut[i]
} else if (out.dims.length === 3) {
for (let i = 0; i < 320 * 320; i++) mask[i] = dataOut[i]
} else {
// 兜底处理
for (let i = 0; i < 320 * 320 && i < dataOut.length; i++) mask[i] = dataOut[i]
}
return { mask }
}
// 返回 session 和推理方法
return { session, inferFromImageData }
}
ort.env.wasm.wasmPaths的设置非常重要。inferFromImageData其实放GPU里计算可能更好,不过又不是不能用先这样。
WebGL 渲染合成
- 准备两个纹理:
uVideo(原视频帧),uMask(320×320 单通道装到 RGB) - 顶点着色器绘制全屏四边形;片段着色器采样
uMask做mix - 在初始化时:
gl.clearColor(0.09,0.10,0.12,1)+gl.clear(...);gl.pixelStorei(gl.UNPACK_FLIP_Y_WEBGL, true)
- 每帧:
gl.texImage2D(..., video)上传视频;- 将
mask[i](0..1)量化成Uint8,打包成 RGBA 上传; - 设置
uVideoSize/uScale/uOffset,调用drawArrays。
// 顶点着色器源码
export const VS = `
attribute vec2 a_pos; // clipspace
attribute vec2 a_uv; // 0..1
varying vec2 v_uv;
void main(){
v_uv = a_uv;
gl_Position = vec4(a_pos, 0.0, 1.0);
}`
// 片元着色器源码
export const FS = `
precision mediump float;
varying vec2 v_uv;
uniform sampler2D uVideo; // full-res video frame
uniform sampler2D uMask; // 320x320 mask (R channel)
uniform vec2 uVideoSize; // [w,h] in pixels
uniform float uScale; // letterbox scale factor s = min(320/w, 320/h)
uniform vec2 uOffset; // [ox, oy] in pixels inside 320x320
uniform bool uShowAlpha;
uniform vec3 uBgColor; // background color when compositing
// 采样 mask 贴图,返回 alpha 值
float sampleMask(vec2 uv){
// 将屏幕 uv(也是视频 uv)映射到模型输入 uv(320x320,带信箱)
vec2 px = uv * uVideoSize; // 视频像素坐标
vec2 modelPx = px * uScale + uOffset; // 模型输入像素坐标
vec2 muv = modelPx / 320.0; // 归一化
float m = texture2D(uMask, muv).r; // 读取 R 通道
return clamp(m, 0.0, 1.0);
}
void main(){
vec4 src = texture2D(uVideo, v_uv);
float a = sampleMask(v_uv);
if (uShowAlpha) {
gl_FragColor = vec4(a, a, a, 1.0);
} else {
vec3 comp = mix(uBgColor, src.rgb, a);
gl_FragColor = vec4(comp, 1.0);
}
}`
完了大概就这样